⚠️ Tämä teksti on tekoälyn tekemä käännös alkuperäisestä englanninkielisestä sisällöstä.
Insinööriasiakkaiden kanssa työskennellessä tyypillinen ETL-skenaario on lukea säännöllisin väliajoin saapuvia datatiedostoja, yleensä CSV- tai Excel-muodossa, ja ajaa ne ETL-putken läpi. Asiakas saattaa muokata dataa käsin jossakin vaiheessa, tai se voi tulla automaattisesti toisesta järjestelmästä. Vaikka datan striimaaminen jotenkin muuten kuin staattisina tiedostoina olisi luultavasti parempi ratkaisu, toimitustapaa ei useinkaan pääse itse valitsemaan. Tarvitaan siis tehokas tapa ladata joukko tiedostoja, poimia niistä data, tehdä tarvittavat muunnokset ja tallentaa lopputulos tietokantaan.
DataFramen käyttötapaukset
Pythonilla työskennellessä, kuten me teemme, kätevin vaihtoehto tällaiseen datankäsittelyyn on käyttää dataframe-kirjastoa kuten Pandas tai Polars. DataFrame on tietorakenne, jossa on sarakkeita ja rivejä, joten CSV-datan esittäminen sillä on varsin luontevaa. Tämän blogikirjoituksen esimerkeissä käytän Polars-kirjastoa. Pidän sitä henkilökohtaisesti tehokkaampana ja intuitiivisempana kuin Pandasia, mutta samat periaatteet pätevät lähes kaikkeen dataframe-työskentelyyn. DataFramejen käyttö erottaa muunnoksen poiminnasta: datan muuntamiseen käytetään samanlaista rajapintaa riippumatta alkuperäisestä formaatista, koska dataframe-muoto pysyy samana. Jos haluat vaihtaa Excelistä CSV:hen, saatat selvitä pelkästään vaihtamalla funktion, jolla data ladataan.
Käytännössä Polars-DataFramen lukeminen Excelistä näyttää tältä:
pl.read_excel(
source="data.xlsx",
sheet_name="data",
)
Ja CSV:hen vaihtaminen:
pl.read_csv(
"data.csv",
has_header=True
)
Samalla datalla molemmat tuottavat identtisen DataFramen:
┌────────────┬──────────────┐
│ snake_name ┆ snake_length │
│ --- ┆ --- │
│ str ┆ i64 │
╞════════════╪══════════════╡
│ python ┆ 420 │
│ anaconda ┆ 370 │
│ python ┆ 350 │
│ anaconda ┆ 520 │
└────────────┴──────────────┘
Yleisiä dataframe-käsittelyn sudenkuoppia
Hienoa, vastuiden erottaminen on kaunista, mutta miten DataFramea oikein kannattaa hyödyntää ETL:n varsinaisessa T-osassa?
Vektorisoitujen operaatioiden käyttämättä jättäminen
Ensimmäinen asia, jonka huomaan huonosti kirjoitetussa dataframe-koodikannassa, on silmukoiden käyttö vektorisoitujen operaatioiden sijaan. Sen sijaan, että iteroisit yksittäisiä elementtejä Python-silmukoilla, kannattaa hyödyntää dataframe-kirjaston taustalla olevaa matalan tason toteutusta ja suorittaa laskenta koko DataFramelle kerralla. Jotta Polarsin taustalla oleva Rust pääsee oikeuksiinsa, katsotaan näitä esimerkkejä:
Silmukka DataFramen rivien läpi:
def total_python_length(df):
result = 0
for row in df.iter_rows(named=True):
if row["snake_name"] == "python":
result += row["snake_length"]
return result
Sama Polarsin vektorisoiduilla operaatioilla:
def total_python_length(df):
return (
df.filter(
pl.col("snake_name") == "python"
)
.select("snake_length")
.sum()
.item()
)
Ensimmäinen esimerkki käyttää perinteisiä Python-silmukoita ja ehtolauseita kaikkien “python”-nimisten käärmeiden yhteispituuden laskemiseen. Toinen tekee täsmälleen saman, mutta Polarsin filter()- ja select()-funktioilla. Ensimmäinen esimerkki oli noin 10 kertaa hitaampi kuin toinen. Suurilla datamäärillä sillä on väliä.
UDF:ien käyttö, kun select riittäisi
Samankaltainen mutta hieman lievempi variaatio on map_rowsin (tai Pandasin apply) käyttäminen tapauksissa, joissa sitä ei tarvita lainkaan. Funktio map_rows ottaa mielivaltaisen käyttäjän antaman funktion (UDF, user defined function) ja käyttää sitä DataFramen jokaiseen riviin. Useimmiten sitä ei oikeasti tarvita.
result = df.map_rows(lambda row: row[1] * 10)
Tavallinen select-operaatio on tässä tapauksessa noin 40 % nopeampi.
result = df.select(pl.col("snake_length") * 10)
Skeemavalidoinnin puuttuminen
Olettamus, että vastaanotettu data on sellaisenaan puhdasta eikä vaadi skeemavalidointia ennen tietokantaan tallentamista, on iso sudenkuoppa. Koodi saattaa toimia moitteettomasti pitkään, kunnes eräänä päivänä tulee mystinen virhe, koska joku muutti alkuperäistä dataa hyvin hienovaraisesti. Otetaan esimerkki: tässä näkyy kaksi hyvin samankaltaista Excel-tiedostoa. Huomaatko eron?
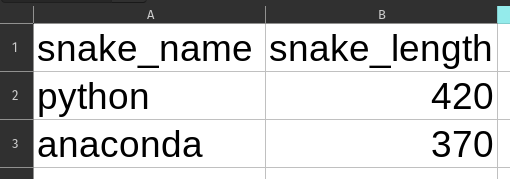
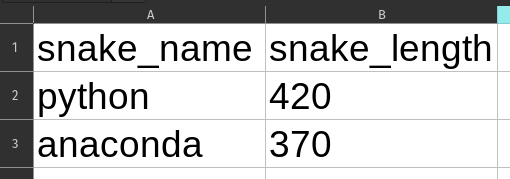
Kyllä — ensimmäisessä käärmeen pituus on numero ja toisessa merkkijono. Varsin yleinen ongelma, kun ihmiset kopioivat dataa eri paikoista. Mitä tapahtuu, kun nämä yritetään ladata DataFrameen?
Ensimmäiselle:
>>> print(df.dtypes)
[String, Int64]
Ja toiselle:
>>> print(df.dtypes)
[String, String]
No niin. Ei mene kovin hyvin yhteen aritmeettisten operaatioiden kanssa.
Yksi ratkaisu on tehdä eksplisiittinen tyyppimuunnos…
df = df.with_columns(
pl.col("snake_length").cast(pl.Int64, strict=False),
)
… mutta yleensä on parempi määritellä skeema alusta asti.
df = pl.read_excel("data.xlsx",
sheet_name="data",
schema_overrides={"snake_length": pl.Int64}
)
Tätä ei voi aina tehdä, mutta se on hyvä lähtökohta. schema_overrides-parametrilla Polars yrittää muuntaa datan määriteltyyn tyyppiin, vaikka alkuperäinen olisi jotain muuta. Jos yksittäisiä arvoja ei voi muuntaa (vaikkapa 370cm pelkän 370:n sijaan), ne muuttuvat hiljaisesti null-arvoiksi.
Järjestyksen olettaminen
Kuten skeemojen kanssa, kannattaa olla eksplisiittinen myös järjestyksen suhteen, varsinkin kun data esitetään ihmiselle. Työskennellään tällä DataFramella, joka on kauniisti järjestetty aikaleiman mukaan:
┌─────────────────────┬────────────┬──────────────┐
│ timestamp ┆ snake_name ┆ snake_length │
│ --- ┆ --- ┆ --- │
│ datetime[ms] ┆ str ┆ i64 │
╞═════════════════════╪════════════╪══════════════╡
│ 2025-01-01 13:00:00 ┆ python ┆ 420 │
│ 2025-01-01 13:05:00 ┆ python ┆ 360 │
│ 2025-01-01 13:15:00 ┆ anaconda ┆ 390 │
│ 2025-01-01 14:20:00 ┆ anaconda ┆ 370 │
│ 2025-01-01 14:45:00 ┆ python ┆ 410 │
└─────────────────────┴────────────┴──────────────┘
Tehdään ryhmittely timestampin tunnin ja snake_namen mukaan:
df.group_by(
pl.col("timestamp").dt.hour().alias("hour"),
"snake_name"
).agg(
pl.col("snake_length").mean().alias("mean_length"),
)
┌──────┬────────────┬─────────────┐
│ hour ┆ snake_name ┆ mean_length │
│ --- ┆ --- ┆ --- │
│ i8 ┆ str ┆ f64 │
╞══════╪════════════╪═════════════╡
│ 13 ┆ python ┆ 390.0 │
│ 14 ┆ python ┆ 410.0 │
│ 14 ┆ anaconda ┆ 370.0 │
│ 13 ┆ anaconda ┆ 390.0 │
└──────┴────────────┴─────────────┘
Huomaa, ettei ensimmäisen sarakkeen mukaista järjestystä enää ole. Polarsin group_by ei säilytä järjestystä oletuksena, joten kokeillaan ensin sitä:
df.group_by(
pl.col("timestamp").dt.hour().alias("hour"),
"snake_name",
maintain_order=True
).agg(
pl.col("snake_length").mean().alias("mean_length"),
)
┌──────┬────────────┬─────────────┐
│ hour ┆ snake_name ┆ mean_length │
│ --- ┆ --- ┆ --- │
│ i8 ┆ str ┆ f64 │
╞══════╪════════════╪═════════════╡
│ 13 ┆ python ┆ 390.0 │
│ 13 ┆ anaconda ┆ 390.0 │
│ 14 ┆ anaconda ┆ 370.0 │
│ 14 ┆ python ┆ 410.0 │
└──────┴────────────┴─────────────┘
Hieman parempi, mutta ei vieläkään kovin johdonmukainen. Tässä piilee myös koukku: maintain_order tekee group_bysta hitaamman ja estää streaming-moottorin käytön, joka normaalisti mahdollistaa RAM-muistia suuremman datan käsittelyn esimerkiksi scan_csvllä read_csvn sijaan.
Paras tapa on olla aina eksplisiittinen järjestyksen suhteen ja (ellei muuta vaadita) lajitella data vasta lopussa, kun se esitetään ihmiselle:
df.group_by(
pl.col("timestamp").dt.hour().alias("hour"),
"snake_name"
).agg(
pl.col("snake_length").mean().alias("mean_length"),
).sort("hour", "mean_length")
┌──────┬────────────┬─────────────┐
│ hour ┆ snake_name ┆ mean_length │
│ --- ┆ --- ┆ --- │
│ i8 ┆ str ┆ f64 │
╞══════╪════════════╪═════════════╡
│ 13 ┆ anaconda ┆ 390.0 │
│ 13 ┆ python ┆ 390.0 │
│ 14 ┆ anaconda ┆ 370.0 │
│ 14 ┆ python ┆ 410.0 │
└──────┴────────────┴─────────────┘
Järjestyksen olettaminen aiheuttaa ongelmia myös toisessa sudenkuopassa: manuaaliset ketjutukset joinin sijaan, mutta se on kokonaan toinen tarina.
Haluatteko tietää lisää?
DataFrameissa riittää sudenkuoppia, mutta oikein käytettynä ne ovat tehokas työkalu. Jos tarvitsette apua suurten CSV- tai Excel-muotoisten tietoaineistojen käsittelyssä tai haluatte optimoida olemassa olevaa dataframe-toteutustanne, ottakaa yhteyttä. Interjektiolla on kokemusta tällaisten käyttötapausten parissa useiden asiakkaiden kanssa, joten tiedämme miten sudenkuopat kierretään.